ABSTRACT¶
This tutorial will guide the user through the creation of population-weighted wealth maps and statistics for administrative areas of interest. After an explanation of micro-level wealth and population estimates, the user will learn to obtain this data for a country of interest alongside the boundaries for the country's administrative areas. These population and wealth data are next joined by location, aggregated to administrative areas, and the wealth data weighted by population. The user is finally guided through validation of their results and exporting the results as maps and tabular statistics. Throughout, the user will be introduced to widely useful Python packages and code as well as Google Earth Engine, a powerful tool for analyzing geographic and satellite imagery.
INTRODUCTION¶
This tutorial is developed following the code and techniques developed by Emily Aiken and Joshua Blumenstock at the University of California, Berkeley. It provides an introduction to the data sources and code required to create population-weighted wealth measures and maps for any country or region of interest.
Introduction to Model-Derived Data Sources¶
For policymakers and NGOs trying to assist the most vulnerable with limited resources, it is of primary importance to have an accurate view of their populations. Traditionally, surveys have been the only way to obtain this information, but the time and expense required for surveys - as well as the speed at which surveys can become outdated due to changing circumstances - make it challenging to identify all individuals in need.
However, with the increasing prevelance of technologies which collect data at scale - including satellites, mobile phones, and WiFi - there are also emerging possibilities for the use of this data. Machine learning models, which can consider and make sense of data on a scale impossible for humans, are being used to combine these observational data with traditional survey responses to expand their usefulness: by providing a model data such as satellite imagery, phone networks, and wifi connectivity alongside ground-truth data collected by surveys, the model can learn what features best identify characteristics such as wealth and population to create predictions for other locations where survey information is unavailable.
Introduction to the Relative Wealth Indices¶
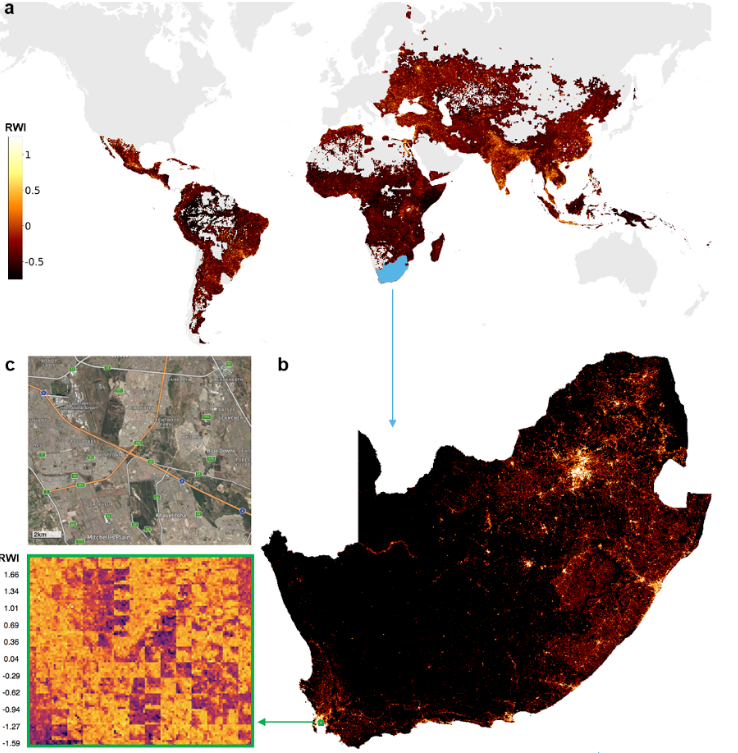
For the wealth data component of this tutorial, we'll use an innovative geographic wealth dataset created from non-traditional sources. The Relative Wealth Index utilizes satellite imagery as well as mobile phone data, topographic maps, and Facebook connectivity data alongside wealth surveys to develop fine-grained (2.4km resolution) estimates of the relative standard of living within countries. Developed as part of a collaboration between UC Berkeley’s Center for Effective Global Action and Facebook’s Data for Good, these wealth estimates for 93 low and middle income countries are made freely available to aid in the work of policymakers and NGOs. See Micro-Estimates of Wealth for all Low- and Middle-Income Countries by Guanghua Chi, Han Fang, Sourav Chatterjee, and Joshua Blumenstock for details of the data creation and validation. Recent work such as this working paper by Emily Aiken, Suzanne Bellue, Dean Karlan, Christopher Udry, and Joshua Blumenstock demonstrate the value of such ML-derived wealth maps.
Introduction to Population Data¶
To overcome the limitations of survey data, many are working to create comprehensive, granular, and accurate population estimates for countries across the globe. One such source is the High Resolution Population Density Maps and Demographic Estimates, which was created as a collaboration between the Center for International Earth Science Information Network (CIESEN) at Columbia University and Facebook Data for Good. These provide estimates of relative population for most countries in the world at 30m resolution and are developed from satellite imagery and census data.
WorldPop's Population Count datasets are another source of nearly-global population data. WorldPop provides an entirely open-access collection of spatial demographic datasets for Central and South America, Asia, and Africa. There are multiple different Population Count datasets provided through WorldPop, with data for individual countries and globally available using either a top-down or bottom-up modelling approach. The top-down approach utilizes collected census data - typically at the level of a particular administrative area - and combines these with geospatial datasets to disaggregate population estimates at 100m or 1km resoultion. These have the benefit of rolling up to administrative level counts which match existing census counts, though countries without a recent census or countries with high mobility will likely have inaccuracies in these counts that will be reflected in the WorldPop estimates. The bottom-up approach instead uses all recent surveys available for an area alongside geospatial datasets to build estimated population counts at 100m resolution. These can provide greater accuracy where census data is outdated or where ground conditions are rapidly changing. For more information on the difference between top-down and bottom-up maps, see WorldPop's explanation of the differences. A final consideration if using the top-down estimates is whether to use data built with a constrained or unconstrained modelling approach. The unconstrained approach produces estimates over the entire land surface, while the constrained approach first limits its estimation to areas already mapped as containing settlements. The constrained approach can result in more accurate population allocation for areas of no population or high population as compared to the unconstrained approach, but it is dependent on accurate settlement mapping, which is not always available. For further discussion on the benefits and costs to using each method, see WorldPop's explanation of the differences. Compared to the High Resolution Population Density Maps described above, WorldPop's Population counts have the additional benefit of providing population data for different years, from 2000-2020. This can be useful if performing any historical analyses requiring population values.

Introduction to Administrative Areas¶
It is often the case that countries are governed and services provided according to hierarchical administrative areas. Recognizing and planning interventions around these areas is thus often useful and necessary for leaders both within and external to each country. There are a few organizations which aim to produce accurate, updated geographic datasets for administrative areas which are available for the use of researchers and policymakers. GADM is one of the most comprehensive of these soruces, providing maps of all countries and associated sub-divisions. The Food and Agriculture Organization's (FAO's) Global Administrative Unit Layers (FAO GAUL) also provides geographic boundaries for administrative units across many countries in the world, with the goal of creating an accurate, standardized source of historical and current administrative areas.

Introduction to Geospatial Data and Tools¶
Data Structure¶
In geospatial data analysis, data can be classified into two categories: raster and vector data. A graphic comparison between raster and vector data can be found in the World Bank Nighttime Lights Tutorial module 2, section 1.
- Raster data: Data stored in a raster format is arranged in a regular grid of cells, without storing the coordinates of each point (namely, a cell, or a pixel). The coordinates of the corner points and the spacing of the grid can be used to calculate (rather than to store) the coordinates of each location in the grid. Any given pixel in the grid stores one or more values (in one or more bands).
- Vector data: Data in a vector format is stored such that the X and Y coordinates are stored for each point. Data can be represented, for example, as points, lines and polygons. A point has only one coordinate (X and Y), a line has two or more coordinates, and a polygon is essentially a line that closes on itself to enclose a region. Polygons are usually used to represent the area and perimeter of continuous geographic features. Vector data stores features in their original resolution, without aggregation.
In this tutorial, we will use vector and raster data. Geospatial data in vector format are often stored in a shapefile, a popular format for storing vector data developed by ESRI. The shapefile format is actually composed of multiple individual files which make up the entire data. At a minimum, there will be 3 file types included with this geographic data (.shp, .shx, .dbf), but there are often other files included which store additional information. In order to be read and used as a whole, all file types must have the same name and be in the same folder. Because the structure of points, lines, and polygons are different, each shapefile can only contain one vector type (all points, all lines, or all polygons). You will not find a mixture of point, line, and polygon objects in a single shapefile, so in order to work with these different types in the same analysis, multiple shapefiles will need to be used and layered. For more details on shapefiles and file types, see this documentation.
Raster data, on the other hand, is stored in Tagged Image File Format (TIFF or TIF). A GeoTIFF is a TIFF file that follows a specific standard for structuring meta-data. The meta-data stored in a TIFF is called a tif tag and GeoTIFFs often contain tags including spatial extent, coordinate reference system, resolution, and number of layers.
More information and examples can be found in sections 3 & 4 of the Earth Analytics Course.
Python and Google Earth Engine for Earth Observation Data¶
One option we'll consider for sourcing administrative areas will be Google Earth Engine. For all necessary Python setup and an introduction to our use of the GEE Python API, see the World Bank Nighttime Light Tutorial, module 2 sections 2-5. In particular, before proceeding you will need to have geemap installed on your machine, and you will need to apply for a Google Earth Engine account here. It may take a day or longer for your Google Earth Engine account to be granted access.
Two of the primary packages we'll be using, Pandas and GeoPandas, must be installed according to their installation instructions: Pandas Installation and GeoPandas Installation. If you're on Windows, GeoPandas installation can occasionally be temperamental - using an environment, as described in the World Bank Nighttime Lights Tutorial, can often circumvent any issues, but if you're still having problems, there are a number of guides online, such as this Practial Data Science guide or this Medium post by Nayane Maia, which provide installation help. Using Windows Subsystem for Linux (WSL) can also make use of tricky packages like GeoPandas easier.
POPULATION-WEIGHTED WEALTH MAPS¶
For this tutorial, we'll demonstrate the process of creating population-weighted wealth estimates for all administrative levels in the country of Jordan. This process can be replicated for any country or region of interest, and the sources of data can be swapped as appropriate to use the most accurate sources of population, wealth, and administrative areas.
Data Ingestion¶
Relative Wealth Indices¶
The relative wealth indices created by Chi et al., which we'll use in this tutorial, can be downloaded as csv files by country from the Humanitarian Data Exchange. To download, find the file associated with your country of interest ('Jordan_relative_wealth_index.csv' for this example) and select 'download'.

Save the relative wealth index file in the same folder as this Python script is saved for easiest use. Once downloaded, we can read our file into Python using the Pandas Python package and convert it to geographic data using GeoPandas. jor_relative_wealth_index.csv is the csv file of Jordan downloaded from the Humanitarian Data Exchange - to utilize a different country's data, replace the file path with the path and name of your file. (Note: only the name of the file is included in this example because the csv file is in the same folder as this Python code. This is leveraging relative paths instead of absolute paths - for more information if you're unfamiliar with relative paths, see this Earth Data Science tutorial).